Disaster Recovery Metrics
Availability
Availability is the percentage of time that the system is online.
- measured of a certain period, typically one year
Downtime is the percentage or amount of time during which the system is unavailable.
- calculated as:
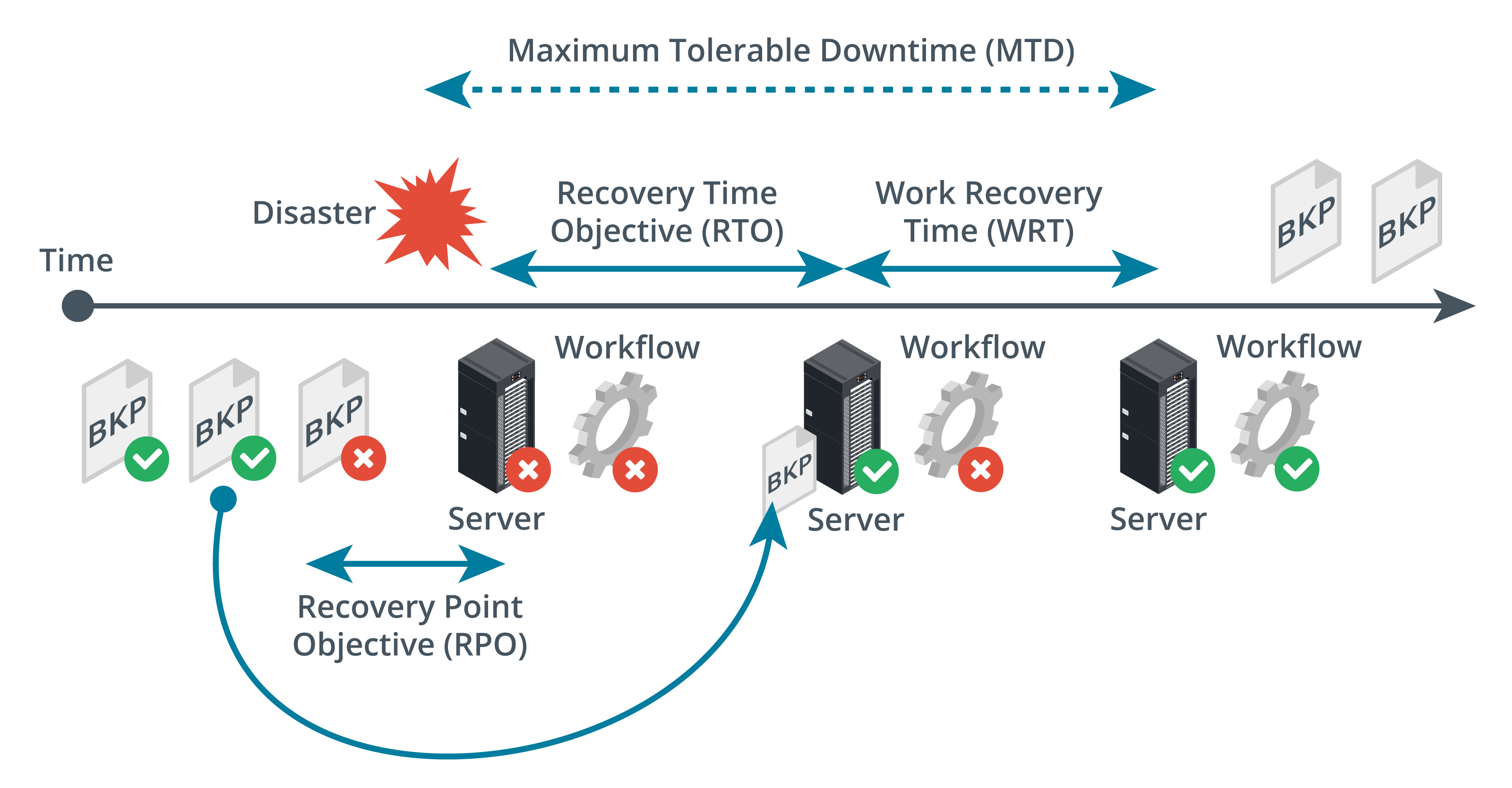
Maximum Tolerable Downtime
Maximum tolerable downtime (MTD) is the longest period that a process can be inoperable without causing irrevocable business failure.
- Each business process can have its own MTD
- high availability is a characteristic of a system that can guarantee a certain level of availability
- may be implemented as 24x7 or 24x365
- critical system availability is described as:
- two-nines (99%) up to six-nines (99.9999%)
| Availability | Annual MTD (hh:mm:ss) |
|---|---|
| 99.9999% | 00:00:32 |
| 99.999% | 00:05:15 |
| 99.99% | 00:52:34 |
| 99.9% | 08:45:36 |
| 99% | 87:36:00 |
- continuous availability refers to a system with no scheduled downtime or outages
- extremely rare
- required when there is not just a commercial imperative, but a danger of injury or loss of life associated with systems failure
- e.g., networks supporting medical devices, air traffic control systems, communications satellites, networked autonomous vehicles, and smart traffic signaling systems
Recovery
- MTD metric sets the upper limit on the amount of recovery time that system and asset owners have to resume operations
- metrics that govern recovery operations:
- recovery time objective (RTO)
- work recovery time (WRT)
- metrics that govern recovery operations:
Recovery Time Objective
Recovery Time Objective (RTO) is the maximum time allowed to restore a system after a failure event.
- is the period following a disaster that an individual IT system may remain offline
- represents the maximum amount of time allowed to
- identify that there is a problem
- and then perform recovery
Work Recovery Time
Work Recovery Time (WRT) is the time additional to the RTO of individual systems to perform reintegration and testing of a restored or upgraded system following an event.
- Following systems recovery, there may be additional work to:
- reintegrate different systems
- restore data from backups
- test overall functionality
- brief system users on any changes or different working practices
Recovery Point Objective
Recovery Point Objective (RPO) is the longest period that an organization can tolerate lost data being unrecoverable.
- the amount of data loss that a system can sustain
- measured in time units
- e.g.,
- if a database is destroyed by a virus
- RPO of 24 hours = data can be recovered from a backup copy to a point not more than 24 hours before the database was infected
- determined by identifying the maximum acceptable data loss an organization can tolerate in the event of a disaster or system failure
- established by considering factors such as:
- business requirements
- data criticality
- and regulatory or contractual obligations
- any data that is lost between the RPO and the present needs to be accepted as a loss or reconstructed
- calculation of RPO directly impacts:
- the frequency of data backups
- data replication requirements
- recovery site selection
- and technologies that support failover and high availability
Recovery Service Level (RSL)
Recovery service level (RSL) is the proportion of a service, expressed as a percentage, that is necessary for continued operations during a disaster.
- e.g., batch image processing service processes 10 images per second
- may decided only 5 images/s is necessary during a disaster
- RSL = 5/10 = 50%
Annualized Loss Expectancy
Annualized loss expectancy (ALE) describes the amount an organization should expect to lose on an annual basis due to any one type of incident.
- ARO = annual rate of occurrence
- SLO = single loss expectancy