Tokenization
Tokenization is a de-identification method where a sensitive data element is substituted with a non-sensitive unique data element, called a token.
- means that all or part of the value of a database field is replaced with a randomly generated token
- token is stored with the original value on a token server or token vault
- is a secure storage system that maintains the relationship between sensitive data and the corresponding tokens
- separate from the production database
- authorized query or app can retrieve the original value from the vault, if necessary
- so tokenization is reversible
- used as a substitute for encryption
- because, from a regulatory perspective, an encrypted field is the same value as the original data
How it Works
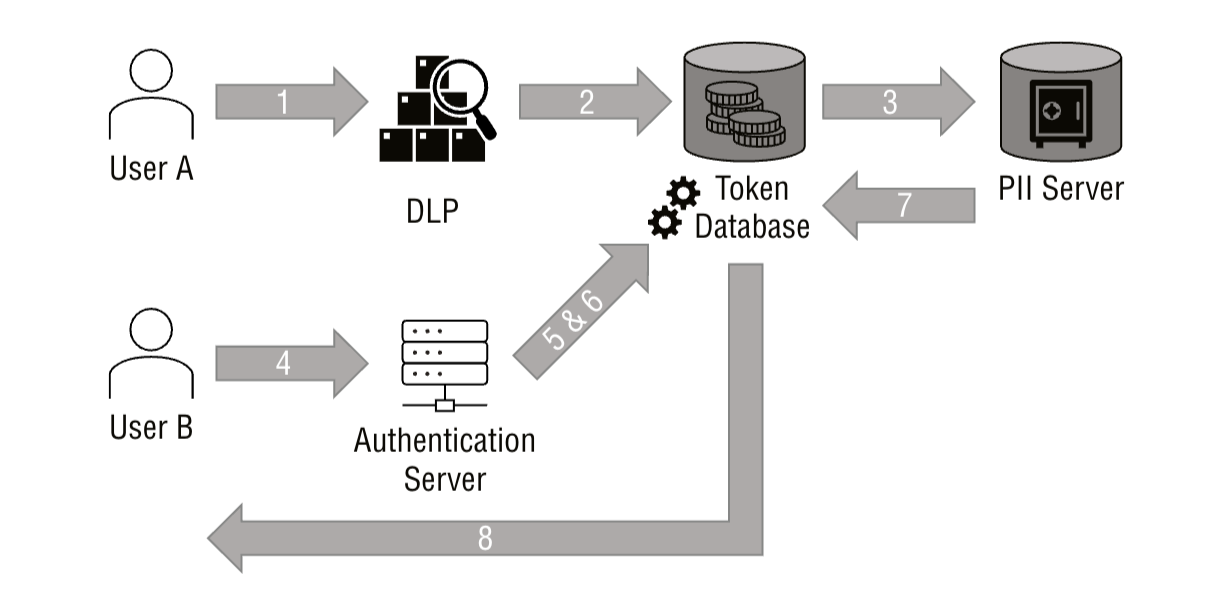
- User A creates a piece of data
- The data is run through a DLP/discovery tool
- aids in determining whether the data is sensitive according to organization’s rules
- if deemed sensitive, it is pushed to a tokenization database
- The data is tokenized
- raw data is sent to the PII server
- a token representing the data is stored in the tokenization database
- token represents the raw data as a kind of logical address
- User B requests the data
- user must be stringently authenticated so the system can determine if the user should be granted access to the data
- If User B authenticates correctly, the request is sent to the tokenization database
- Tokenization database looks up the token of the requested data, then presents the token to the PII database
- The PII database returns the raw data based on the token
- The raw data is delivered to User B