Database Indexes
Table Structures
A table structure is a scheme for organizing rows in blocks on storage media.
- row-oriented storage performs better than column-oriented storage for most transactional databases
- thus relational databases commonly use row-oriented storage
- 4 common table structures:
- Heap table
- Sorted table
- Hash table
- Table cluster
- each table in a database can have a different structure
- databases have a default structure
- administrators can override the default to optimize performance for specific queries
Heap Table
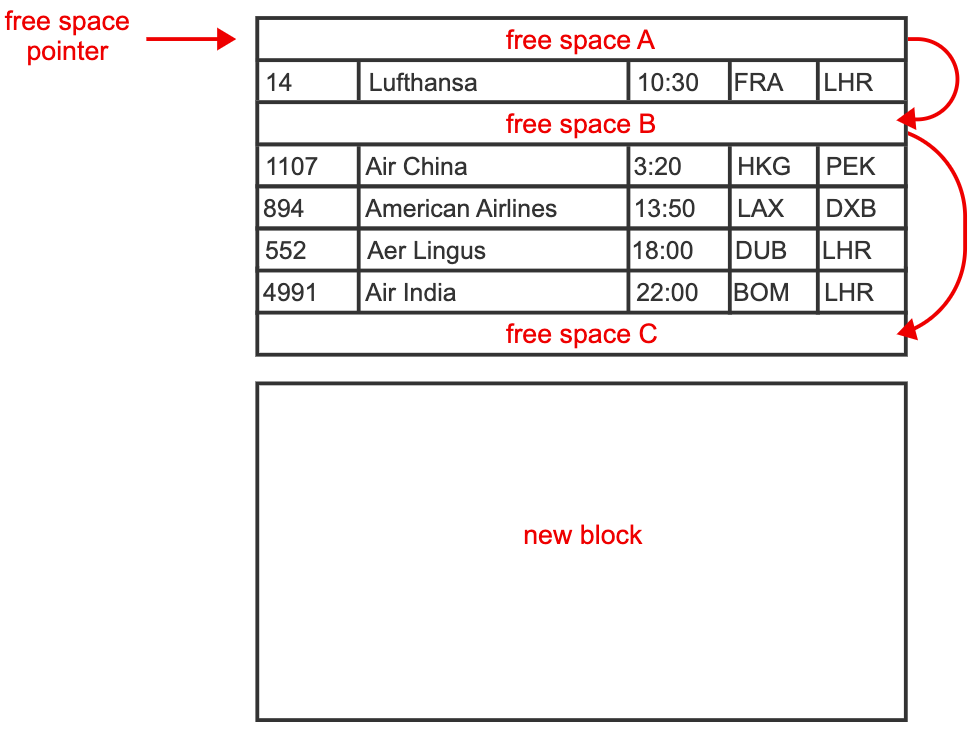
A heap table imposes no order on rows.
- database maintains a list of blocks assigned to the table along with the address of the first available space for inserts
- if all blocks are full,
- database allocates a new block and inserts rows in the new block
- when a row is deleted,
- the space occupied by the row is marked as free
- free space is tracked as a linked list
- inserts are stored in the first space in the list
- the head of the list is set to the next space
- optimizes insert operations
- particularly fast for bulk load of many rows
- since rows are stored in load order
- not optimal for queries that read rows in a specific order
- since rows are scattered randomly across storage media
Heap Table
Sorted Table
In a sorted table, the database designer identifies a sort column that determines physical row order.
- sort column is usually the primary key
- but can be a non-key column or group of columns
- rows are assigned to blocks according to the value of the sort column
- each block contains all rows with values in a given range
- within each block, rows are located in order of sort columns
- sorted tables are optimal for queries that read data in order of the sort column
- e.g.,
JOINon the sort columnSELECTwith range of sort column values in theWHEREclauseSELECTwithORDER BYthe sort column
- e.g.,
- maintaining sort order of rows within each block can be slow
- when a new row is inserted, or when the sort column is updated,
- free space may not be available in the correct location
- when a new row is inserted, or when the sort column is updated,
- to maintain correct order efficiently,
- databases maintain pointers to the next row within each block
- inserts and updates change two address values rather than move entire rows
- when an attempt is made to insert a row into a full block, the block splits in two
- database moves half the rows from the initial block to a new block
- creating space for the insert
- database moves half the rows from the initial block to a new block
- sorted tables are optimized for read queries
- at the expense of insert and update operations
Hash Table
In a hash table, rows are assigned to buckets.
- bucket is a block or group of blocks containing rows
- initially, each bucket has one block
- as a table grows, some buckets fill up with rows and the database allocates additional blocks
- new blocks are linked to the initial block
- bucket becomes a chain of linked blocks
- bucket containing each row is determined by a hash function and hash key
- hash key is a column or group of columns
- usually the primary key
- hash function computes the bucket containing the row from the hash key
- designed to:
- scramble row locations
- evenly distribute rows across buckets
- designed to:
- hash key is a column or group of columns
- modulo function is a simple hash function with 4 steps:
- convert the hash key by interpreting the key’s bits as an integer value
- divide the integer by the number of buckets
- interpret the division remainder as the bucket number
- convert the bucket number to the physical address of the block containing the row
- deep buckets with many linked blocks are inefficient
- to avoid, database may use a dynamic hash function
- automatically allocates more blocks to the table, creates additional buckets, and distributes rows across all buckets
- more buckets = fewer rows per bucket = buckets with fewer linked blocks
- to avoid, database may use a dynamic hash function
- optimal for
- inserts and deletes of individual rows
- because row location is quickly determined by the hash key
- selecting a single row when hash key value is specified in the where clause
- inserts and deletes of individual rows
- slow for queries that select many rows with a range of values
- because rows are randomly distributed across many blocks
Table Clusters
Table clusters interleave rows of two or more tables in the same storage area.
- aka multi-tables
- have a cluster key
- a column that is available in all interleaved tables
- determines the order in which rows are interleaved
- rows with same cluster key value are stored together
- is usually the primary key of one table and the foreign key of another
- optimal when joining interleaved tables on the cluster key
- since physical row location is not the same as output order
- perform poorly for:
- join columns other than cluster key
- in a join on a column that is not the cluster key, physical row location is not the same as output order, so the join is slow
- read multiple rows of a single table
- table clusters spread each table across more blocks than other structures
- reading multiple rows may access more blocks
- update cluster key
- rows may move to different blocks when the cluster key changes
- join columns other than cluster key
- not commonly used
Single-Level Indexes
A single-level index is a file containing column values, along with pointers to rows containing the column value.
- pointer identifies the block containing the row
- may also identify the exact location of the row within the block in some indexes
- indexes are created by database designers with
CREATE INDEXcommand - normally sorted on the column value
- sorted index is no the same as an index on a sorted table
- e.g., index on a heap table is a sorted index on an unsorted table
- if index column is unique,
- index has one entry for each column value
- if index column is not unique,
- index may have multiple entries for some column values
- or one entry for each column value, followed by multiple pointers
- index is usually defined on a single column
- but can be multiple
In a multi-column index, each index entry is a composite of values from all indexed columns.
- behave exactly like indexes on a single column
Query Processing
- to execute a
SELECTquery, a database can perform a:- table scan
- is a database operation that reads table blocks directly, without accessing an index
- index scan
- is a database operation that reads index blocks sequentially, in order to locate the needed table blocks
- table scan
Hit ratio is the percentage of table rows selected by a query.
- aka filter factor or selectivity
- when a
SELECTquery is executed,- the database examines the
WHEREclause and estimates hit ratio - if ratio is high, performs a table scan
- if ratio is low, the query needs only a few table blocks, so:
- looks for an indexed column in the
WHEREclause - scans the index
- finds values that match the
WHEREclause - reads the corresponding table blocks
- looks for an indexed column in the
- the database examines the
- if the
WHEREclause does not contain an indexed column,- the database must perform a table scan
- index requires fewer blocks than a table
- bc column value and pointer occupy less space than an entire row
- index scans are much faster than table scans
- some cases, indexes can be small enough to reside in main memory, and scan time is insignificant
- When hit ratio is low,
- additional time to read the table blocks containing selected rows is insignificant
Binary Search
In a binary search, the database repeatedly splits the index in two until it finds the entry containing the search value.
- how it works:
- database first compares the search value to an entry in the middle of the index
- If the search value is less than the entry value,
- the search value is in the first half of the index
- If not, the search value is in the second half
- database continues in this manner until it finds the index block containing the search value
Primary and Secondary Indexes
- indexes on a sorted table can be:
- primary index
- is an index on a sort column.
- aka clustering index
- sorted table can have only one sort column
- thus only one primary index
- usually is on the primary key columns
- secondary index
- is an index that is not on the sort column.
- aka non-clustering index
- tables can have many secondary indexes
- all indexes of a heap or hash table are secondary
- since they have no sort column
- primary index
- indexes can be:
- dense index
- contains an entry for every table row
- secondary indexes are on non-sort columns
- thus always dense
- sparse index
- contains an entry for every table block
- primary indexes are on sort columns and usually sparse
- much faster than dense
- have fewer entries and occupy fewer blocks
- dense index
Inserts, Updates, and Deletes
- Inserts, updates, and deletes to tables have an impact on single-level indexes
- Consider the behavior of dense indexes:
- insert
- When a row is inserted into a table, a new index entry is created
- Since single-level indexes are sorted, the new entry must be placed in the correct index block
- If this block is full, the block splits in two to create space for the new index entry
- delete
- When a row is deleted, the row’s index entry must be deleted
- deleted entry can be either physically removed or marked as ‘deleted’
- Since single-level indexes are sorted, physically removing an entry requires moving all subsequent entries, which is slow
- For this reason, index entries are marked as ‘deleted’
- database may reorganize the index to remove deleted entries and compress the index, periodically
- update
- An update to a column that is not indexed does not affect the index
- An update to an indexed column is like a delete followed by an insert
- index entry for the initial value is deleted and an index entry for the updated value is inserted
- insert
- With a sparse index,
- each entry corresponds to a table block rather than a table row
- index entries are inserted or deleted when blocks split or merge
- Since blocks contain many rows, block splits and mergers occur less often than row inserts and deletes
- aside from frequency, behavior of sparse and dense indexes is similar